绿联NAS突发故障:从硬盘集体损毁到SATA控制器排查
突发故障回顾
2026年2月5日,一个平静的周四,我的 HomeLab 突然遭遇了一场”灾难”——绿联 NAS 忽然离线,所有硬盘报告已损毁。
从收到 Pushover 告警开始,到最终判断为 SATA 控制器硬件故障,再到经历售后沟通、维修波折,最终免费换新。整个过程记录下来,希望能给遇到类似问题的朋友一些参考。
故障时间线
10:30 — 第一声警报
手机忽然收到 Pushover 告警:绿联设备心跳消失。
10:32 — 连锁反应
Nextcloud 率先”崩溃”——因为依赖的 NFS 服务(即 NAS)消失了,大量服务开始连锁报警。
Pushover 消息疯狂推送,整个 HomeLab 像多米诺骨牌一样倒下。这时我才意识到,这不仅仅是 NAS 的问题,而是整个存储层的故障。
12:30 — 回家发现 NAS 关机
中午赶回家,发现绿联 NAS 已经自动关机了。我按下电源键重启,设备启动正常,但进入系统后,我看到了让人心跳加速的一幕:
所有硬盘全部报告”已损毁”。
那一刻我的大脑一片空白。四个硬盘同时损坏?这是什么概率?
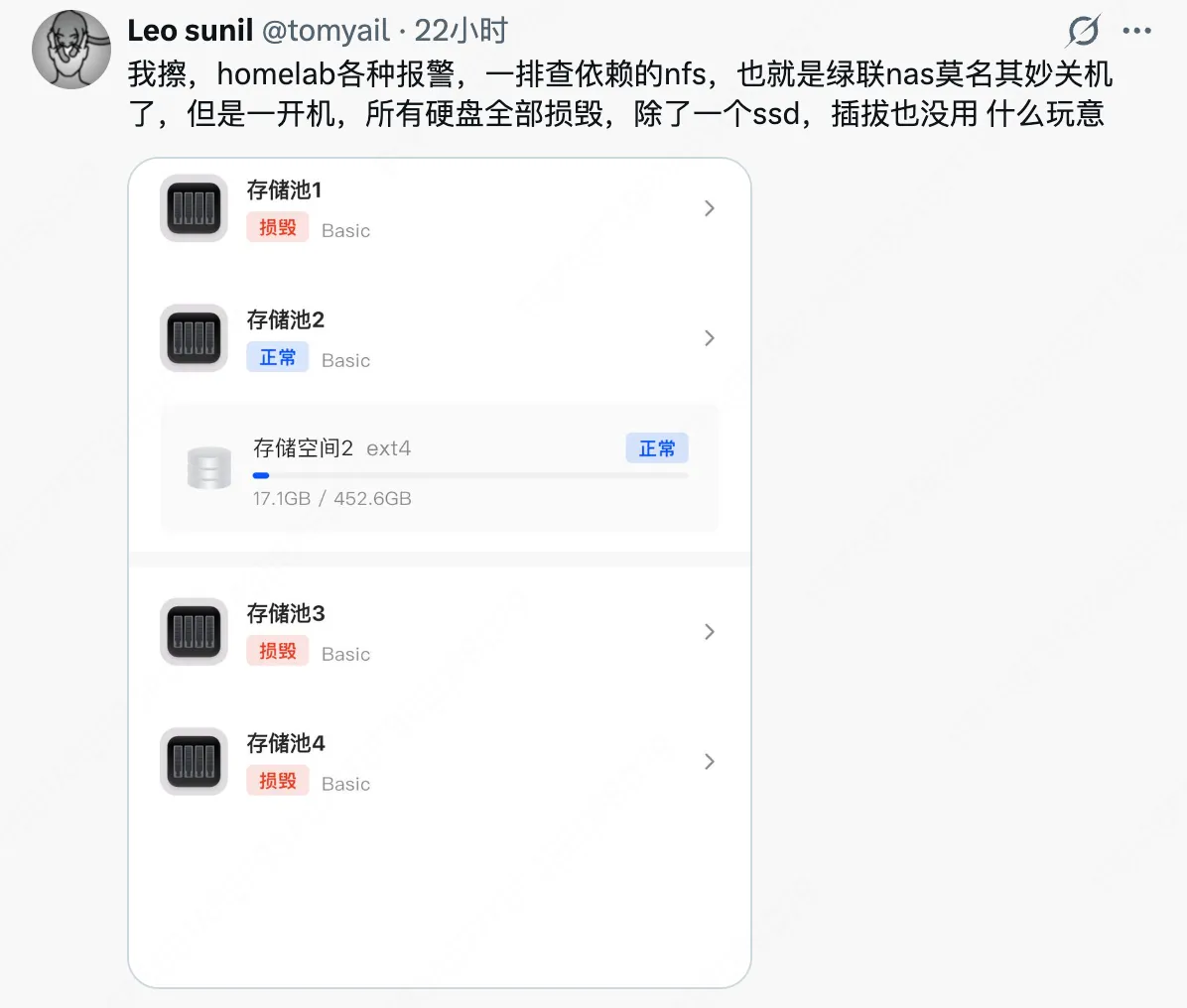
我赶紧发了个推文压压惊(上图),然后强迫自己冷静下来思考。
排查思路:从怀疑到验证
疑点浮现
冷静下来后,我梳理出两个核心疑点:
- 为什么 NAS 会忽然断电? — 设备就在家里,没有断电,没有人动它
- 为什么全部硬盘同时”挂了”? — 三个硬盘同时故障的概率太低了
第一个念头:中毒了?
前一天我刚好配置了 VPS 的 restic 备份同步到 NAS 的 MinIO 服务。看到硬盘全部”损毁”,我第一时间想到的是:
会不会是 MinIO 的 token 被盗,黑客入侵了 MinIO,然后控制了整个 NAS,把硬盘都加密了?
这个念头让我更加紧张。但很快我就否定了这个假设——如果是勒索病毒,应该会有勒索信息,而不是默默地把硬盘”标记”为损坏。
硬件验证:数据还在吗?
得先确认数据是不是真的丢了。问题来了:
- 绿联给每个盘设置了软 RAID
- 硬盘格式是 btrfs
- Mac 和 Windows 都不能直接读取
我找了硬盘盒把硬盘拆下来连接到电脑上,果然读不出来。
这时我想到了 Claude Code。通过它,我:
- 启动 Docker 运行 btrfs 工具
- 验证硬盘分区能被识别
- 确认文件目录都存在
结论:硬盘数据完好!
这说明硬盘本身没有物理损坏,“已损毁”应该是软件层面的判断。
日志分析:找到线索
绿联系统是基于 Debian 改的,Claude Code 搞 Linux 很熟。让它分析了一下 NAS 日志,结论是:
可能是 SATA 控制器故障,导致主板无法识别任何硬盘
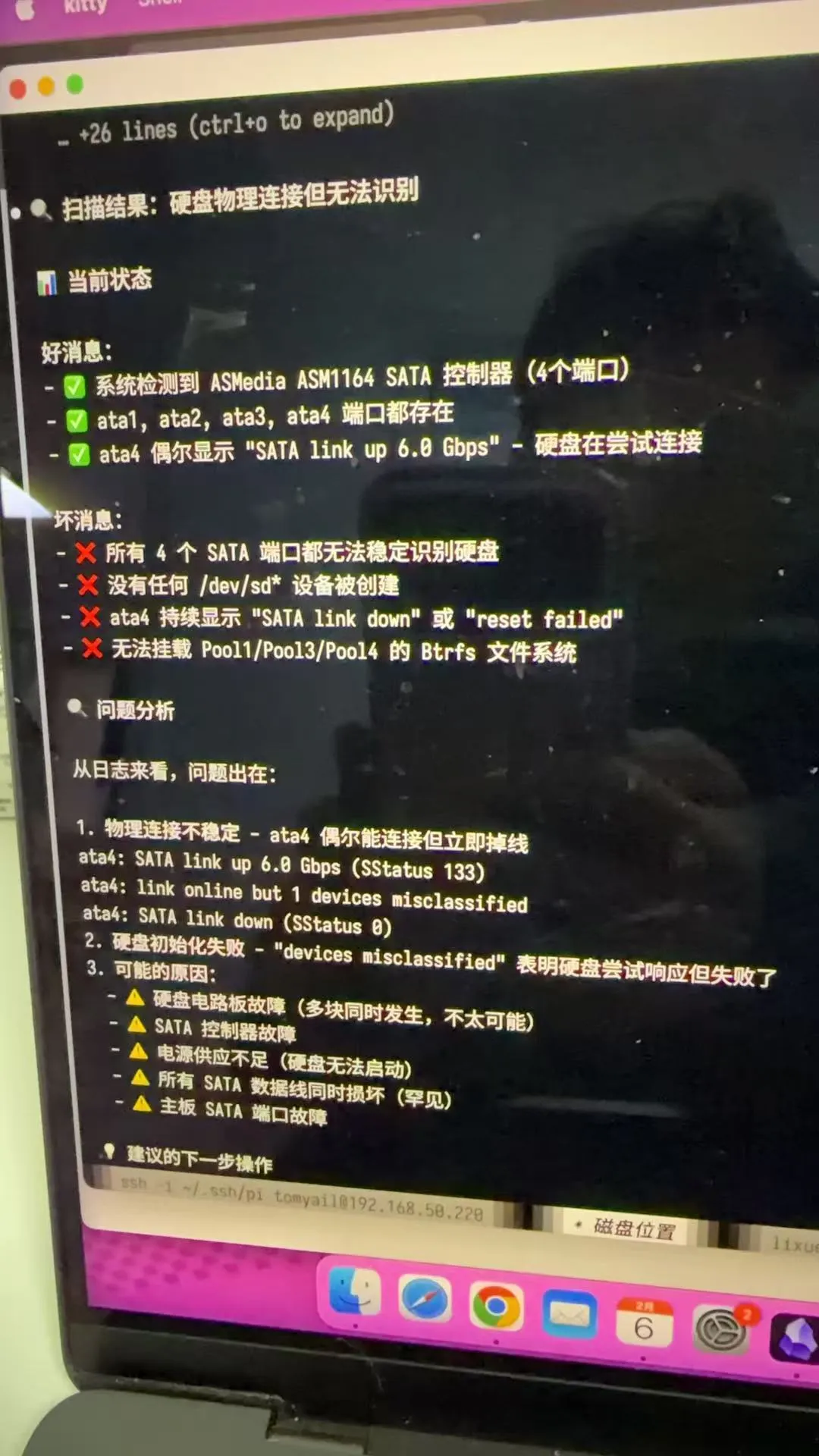
这个判断说得通。硬盘坏了,新插的测试盘应该能识别;但 SATA 控制器坏了,插什么都读不出来。
我验证了一下:插入自己的测试硬盘,NAS 也识别不了。
结论确认:不是硬盘问题,是主板 SATA 控制器问题。
售后沟通记录
2 月 6 日:联系绿联售后
虽然我基本判断是硬件问题,但这台 NAS 是 2024 年双十一在京东购入的,找京东售后比较稳妥。
早上9点多联系京东绿联客服,对方告知需要添加”绿联私有云”公众号 → 技术服务,我按指引联系后,响应很快,告知需要”进入底层进行问题排查”,引导我完成以下准备工作:
- 创建临时管理员账号(控制面板 → 用户管理 → 新增用户,建议设置非常用密码,问题处理后及时删除)
- 开启 SSH 功能(控制面板 → 终端机 → SSH → 启用)
- 提供 SSH 远程识别码(帮助中心 → 辅助工具 → 启用远程访问 → 启用调试模式)
售后 SOP 操作
给了相关信息后,技术客服让我按标准流程操作:
- 重启 NAS,重新插拔硬盘 — 无效
- 查看系统版本,升级到最新系统 — 无效
- 最终判断:金手指有灰尘,需要拆机清洁

前两个操作我其实心里早就知道没用,但还是礼貌性地配合了。第三个判断让我有点纳闷:
SATA 金手指不是一直插在主板上吗?怎么会忽然”有灰”导致所有 SATA 口都识别不了?
不过当时手头没有工具拆机,只能答应有时间再操作。
时间尴尬点
更尴尬的是,客服告诉我:
2月份工厂基本没人,要返厂的话得等到3月份
看来绿联不是血汗工厂啊 🤣
维修过程波折
2 月 24 日:联系京东申请维修
春节过完,决定走京东售后流程,直接申请维修。
2 月 26 日:京东确认只换新不维修
京东收到货后告知,提出换新不维修,我想了下这不是让我免费用一年产品吗,当然同意了。老 NAS 是 2024 年双十一买的,用了一年多,这次相当于免费用了一年。
不过因为之前我是按照维修而不是换新的方式申请的,老的 NAS 加装的 SSD 硬盘并没有取出来,而且老的电源线等配件都被同时寄给了快递。
技术确认
绿联存储使用的结构:
- 底层:软 RAID (mdadm)
- 中层:LVM
- 上层:btrfs
维修沟通波折
2 月 28 日(周六)
客服电话通知,说维修部没有发现 NAS 里面还有额外的存储。我很诧异——绿联的售后难道连自己产品的设计都不清楚吗?
我告诉客服,我加装的 SSD 在机器底部,需要拆开底下的螺丝才能拿出来。客服表示会反馈给维修部。
3 月 1 日(周日)
手机开了勿扰,京东的电话都没接到。
3 月 2 日(周一)
主动询问绿联客服。客服又来电话,说售后部门从底下拆出了两个部件,不确定哪个是。
emmm,难道售后看不出哪根是 SSD,哪根是内存条吗?
让客服加了我微信,她拍了照片让我指认。确认后,客服问我旧的网线、电源线是否还在。
我说电源线和防尘盖子都在,但网线不确定——家里网络设备太多,网线会混用。
客服说直接换新,旧的电源线也不用退了。
后续与新机配置
设备到手
新的 NAS 到货后,我开始了重新配置的过程。

数据迁移
由于绿联的存储结构(mdadm + LVM + btrfs),新 NAS 可以直接识别老硬盘上的数据。这大大简化了迁移过程:
- 将原来的硬盘插入新 NAS 对应的槽位
- 新 NAS 启动后转换为内部存储
- 数据完好无损
服务迁移
由于所有数据都在原来的硬盘上,大部分服务可以快速恢复:
- Docker 容器重启(因为 Docker Compose 配置在硬盘上)
- 音视频不需要重新索引
- 照片需要重新索引
经验教训与思考
监控的价值
要不是 Pushover 告警,我可能要晚上回家才发现 NAS 挂了。虽然监控解决不了问题,但至少能第一时间知情。
建议:给关键服务配上心跳监控
排查思路
所有硬盘同时”损坏”,多半是控制器问题,不是硬盘问题。
- 单个硬盘损坏 → 硬盘问题
- 所有硬盘同时损坏 → 控制器/主板问题
AI 辅助诊断
Claude Code 这次帮了大忙:分析日志、验证数据、给排查思路。
AI 不能替代专业诊断,但信息收集和初步分析阶段确实好用。现在我的习惯是:遇事不决,Claude Code 启动。
备份:惨痛教训
这次数据没丢,但让我重新思考备份策略。
之前的想法:NAS 不同硬盘上备份就行了,毕竟 NAS 整个挂掉的概率不大。
现实:这次还真的就是整个 NAS 出问题——四个硬盘都没坏,但 SATA 控制器挂了,所有硬盘同时”消失”。同台 NAS 上的 Borgmatic 备份根本救不了。
新策略:
- 必须异地备份:照片这种不能丢的数据,备份到云端(加密)或另一台设备
- 3-2-1 原则:3 份副本、2 种介质、1 份异地——这次我算懂了”1 份异地”的份量
- 文件系统的坑:btrfs + 软 RAID 出问题时只能在 Linux 上操作,Mac 和 Windows 没辙